StackOverdrive´s clients commonly save 30%-40% on infrastructure costs after StackOverdrive completes a cloud migration or cloud cost optimization of their infrastructure. Although actual savings depend on the state of your infrastructure beforehand, StackOverdrive´s Cloud Cost Management services are designed for robustness, scalability, and security, and in doing so, we are usually able to create an infrastructure that is significantly cheaper than common naive infrastructure patterns.
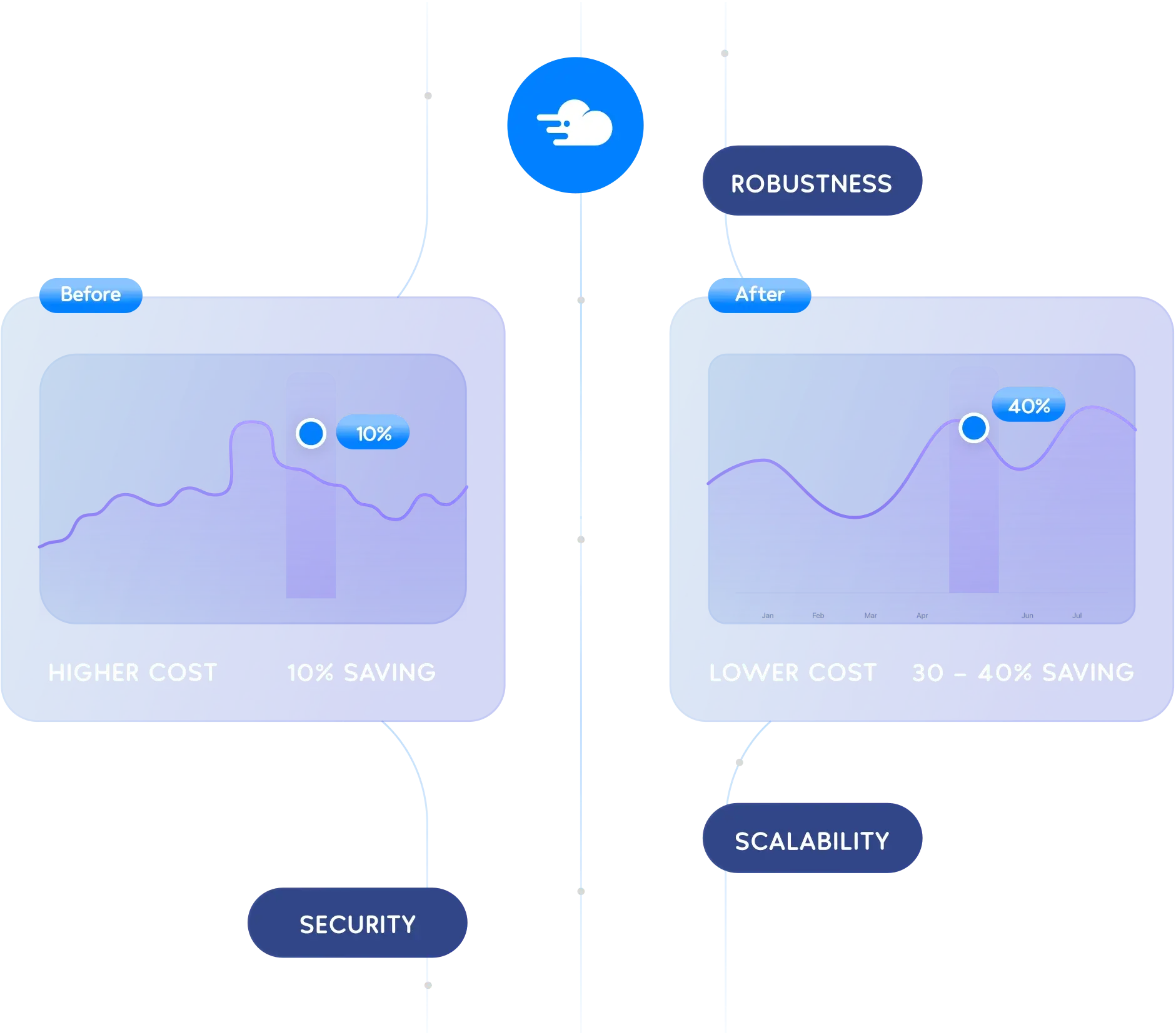
The most common way that organizations provision cloud computing resources is by provisioning a specific, fixed number of computer instances with their cloud providers, using the on-demand option (or equivalent). To achieve easier management, typically, each instance will be provisioned for a single purpose, and the number of instances will be chosen to hit a theoretical or historical maximum load.
Let´s talk about the problems with this kind of setup and how we solve them.


back to top